→ naviguer · o vue · p présentateur · f plein écran
Genève · agence digitale indépendante
2023 · 2026
BB®
Switzerland.
Une maison où l’on conseille avant de coder, et où l’on code sans jamais déléguer le sens.
Des marques qui paient pour de la singularité et de la confiance.
Clients



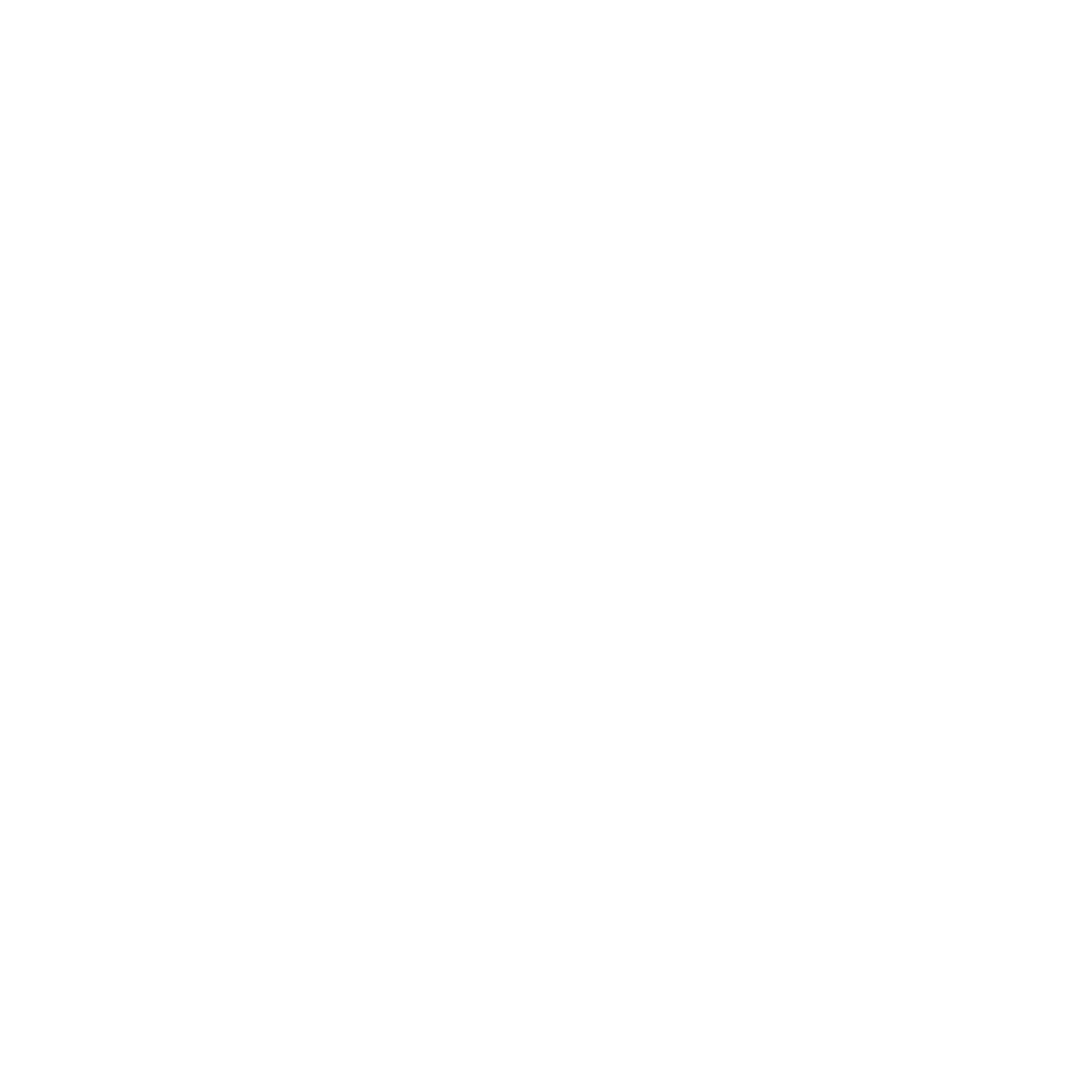






















Pôles
Digital & Web · Marketing · Graphisme & Design · Photos & Vidéos
Stack
WordPress · Nuxt · Symfony · Next.js
Au moment de l’étude : aucune brique IA centralisée dans l’infrastructure de l’agence.
Cinq pressions,
un même angle mort.
Aucune ne se résout en silo. C’est leur convergence qui exige une architecture.
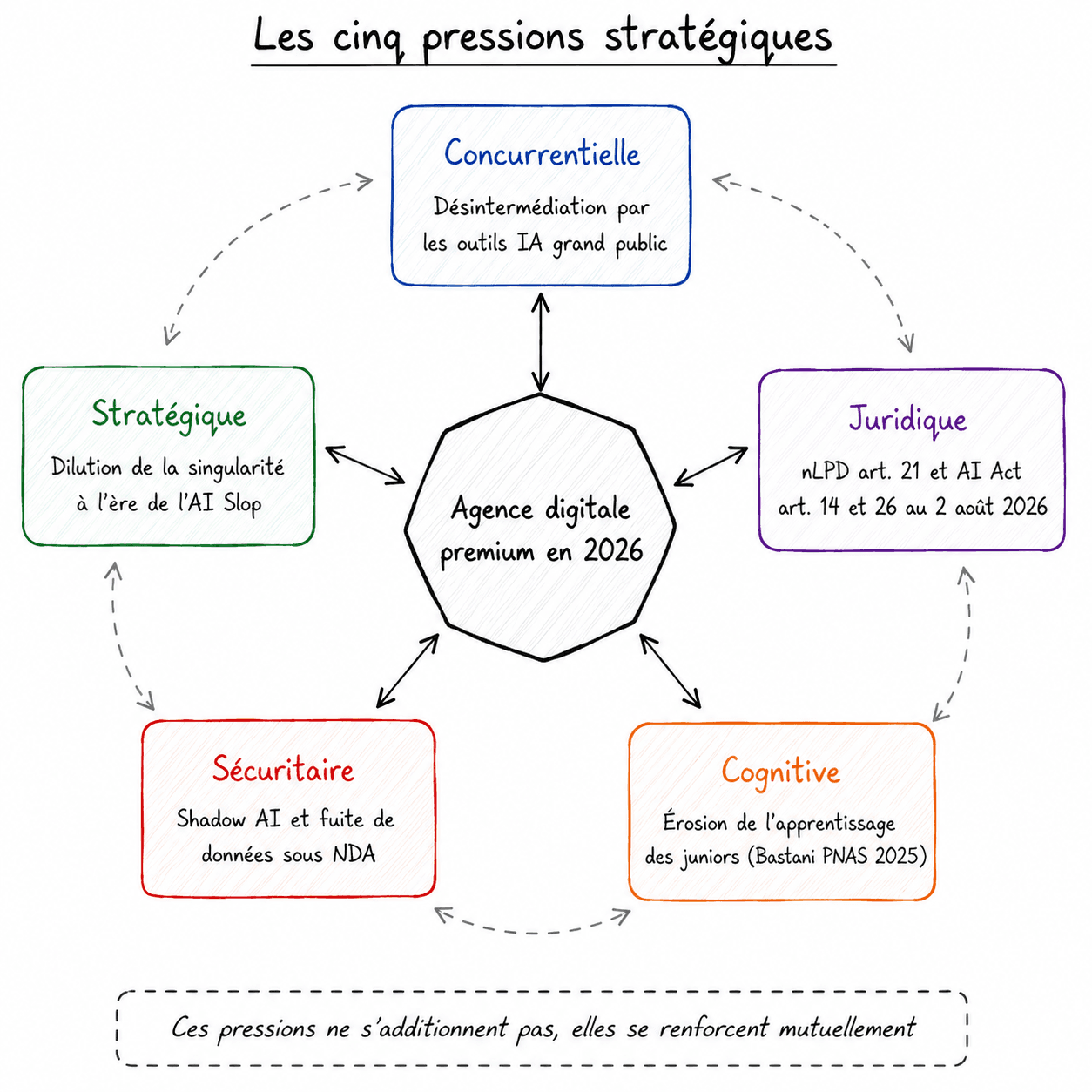
L’IA propose. L’humain dispose.
Quatre nœuds spécialisés + un point d’arrêt humain.
Retriever
Recherche vectorielle dans ChromaDB. Récupère les passages pertinents.
Generator
Claude Sonnet 4.5. Produit une réponse à partir des passages.
Critic
Audit auto : score de confiance, ancrage, alertes actionnables.
HITL Checkpoint
interrupt(). L’humain voit la réponse, le rapport, les sources.
Executor
Matérialise l’action, uniquement après validation humaine.
Pourquoi pas un seul appel LLM ?
Un seul appel LLM fait tout d’un bloc, sans aucune prise pour l’humain.
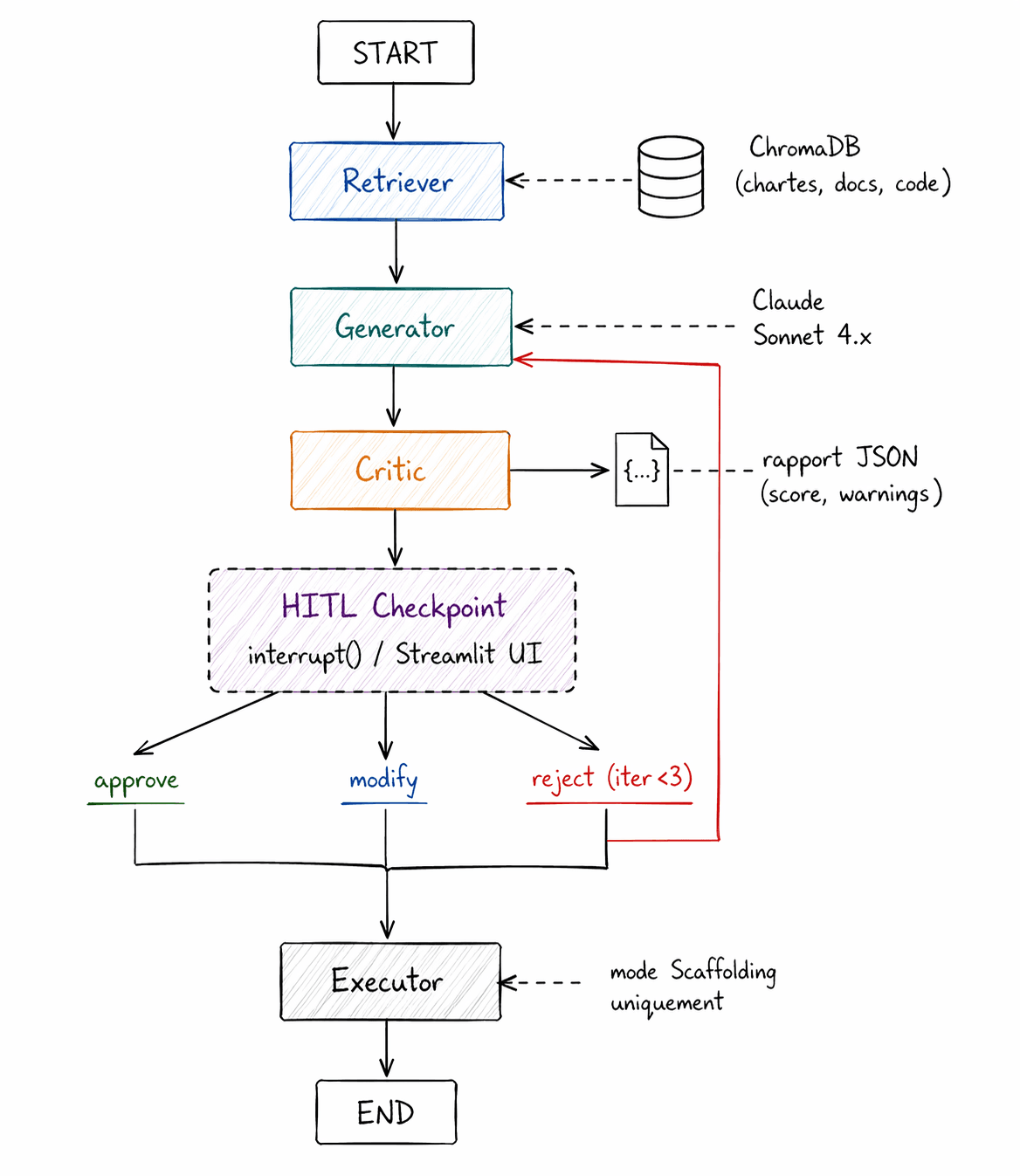
RAG souverain · corpus local indexé, recherche vectorielle.
Point d’arrêt · obligatoire avant tout effet de bord.
Trace complète · qui, quand, quoi, pourquoi.
Aucune donnée brute ne sort.
La souveraineté n’est pas un principe. C’est une contrainte architecturale.
Corpus local · chartes PDF, Docusaurus, archives GitHub indexés en interne.
Cloud filtré · seuls les top-k passages anonymisés transitent vers l’API LLM.
Conformité nLPD · Privacy by Design imposé par l’article 7.
Trois gestes, trois signaux.
Capture du POC BB® en mode Question, l’humain valide, corrige ou relance avant toute livraison.
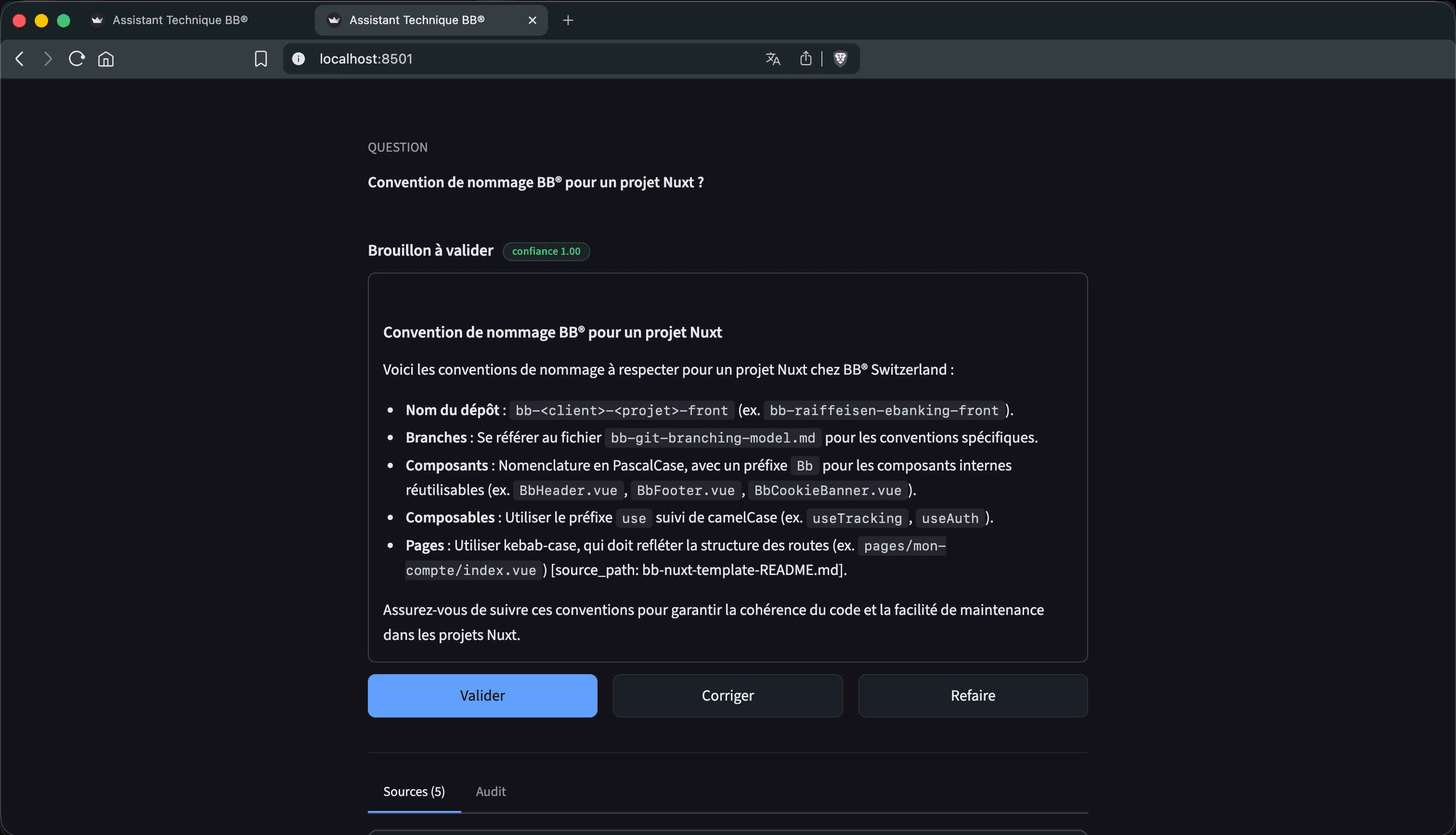
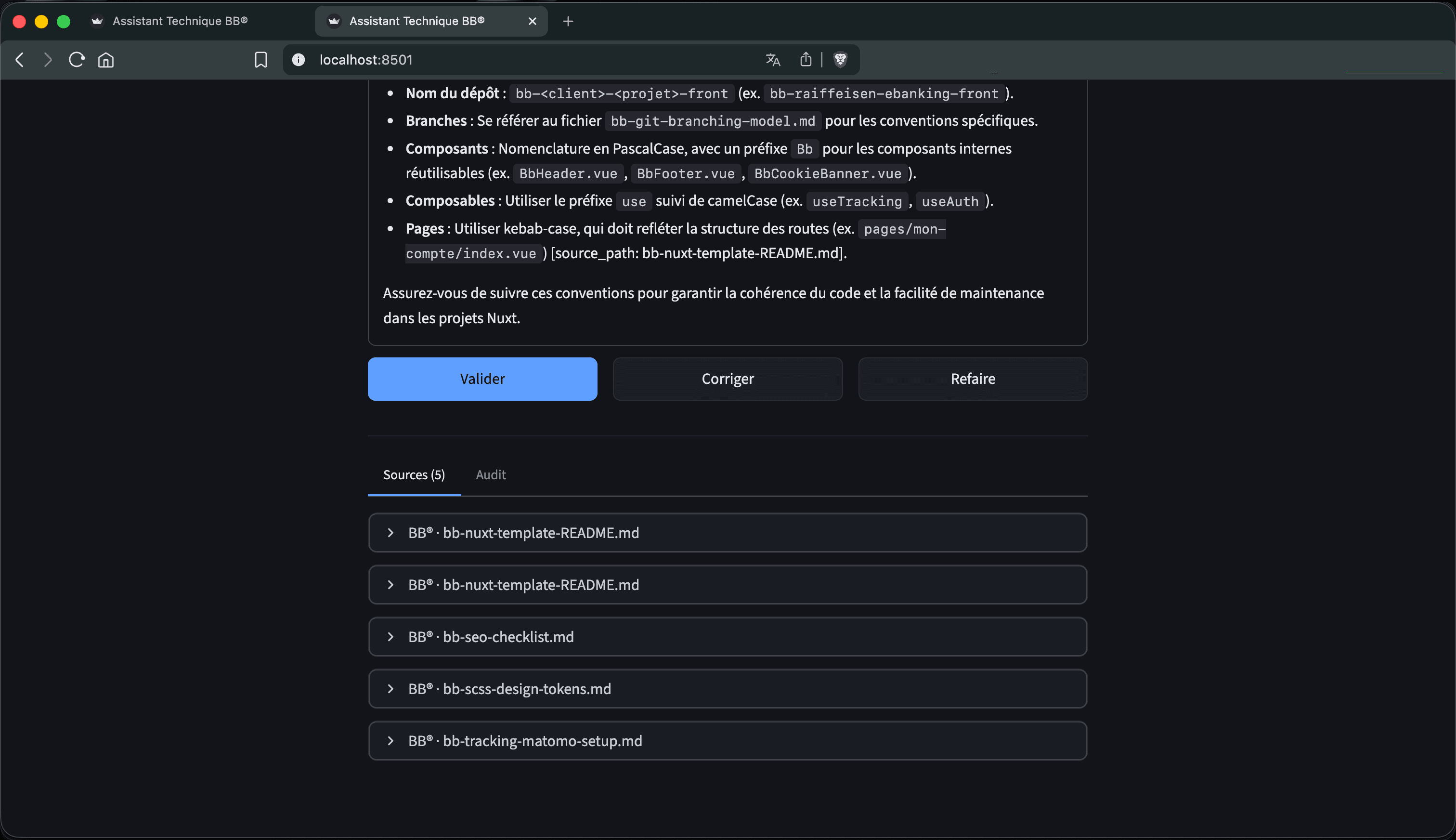
Valider
La réponse part au client telle quelle.
Corriger
L’expert édite. Le delta nourrit la boucle.
Refaire
Le Generator repart avec le feedback (iter < 3).
Chaque décision est horodatée et signée. Le delta proposition / validation est tracé, scoré, réinjecté dans le corpus.
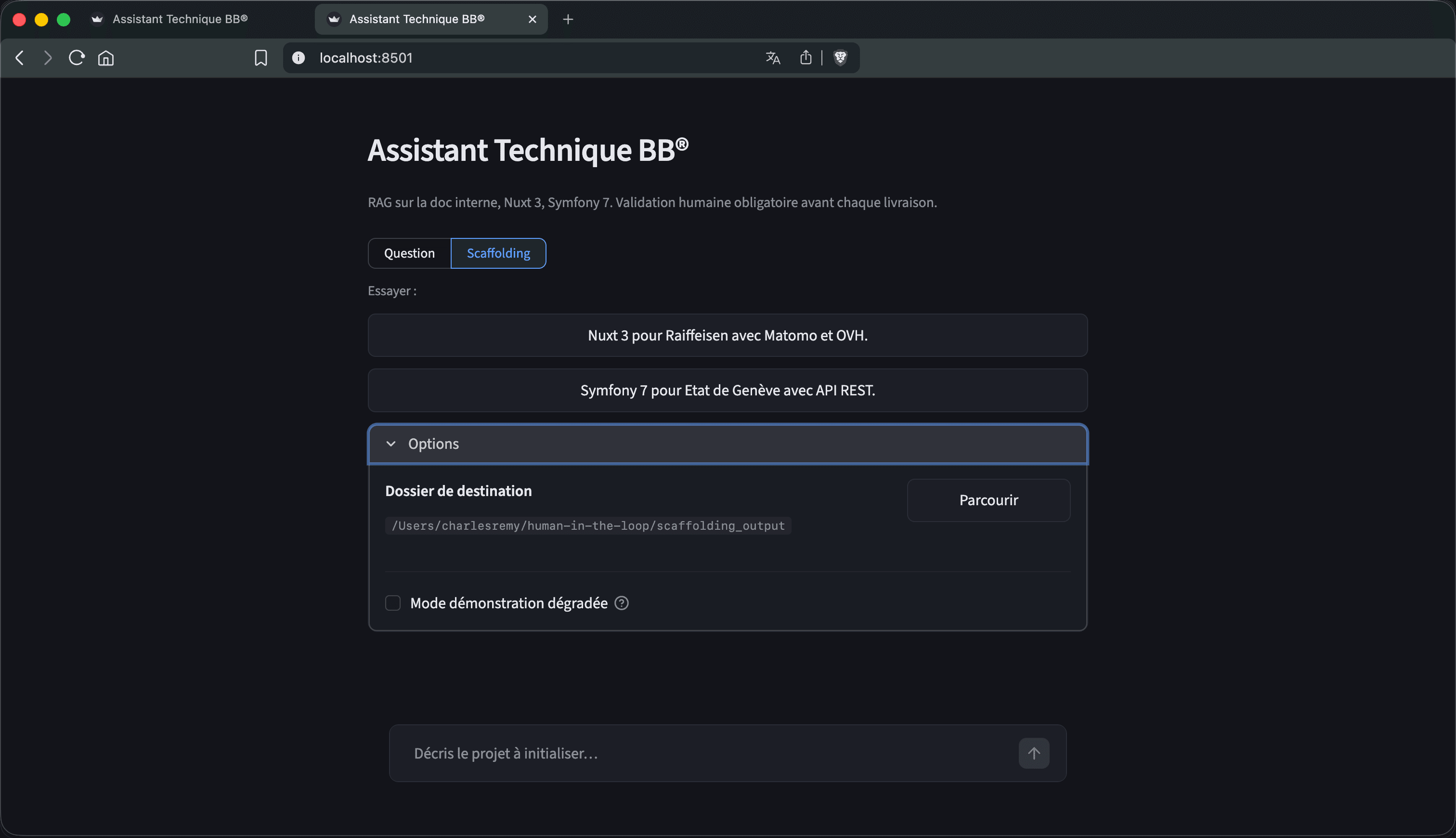
Deux modes, une boucle.
Un POC fonctionnel, testable, open source. Au service d’une agence qui ne pouvait pas attendre.
Mode 01
Question
RAG factuel sur corpus métier · citations sourcées obligatoires.
Mode 02
Scaffolding
Génération de structures projet · validation HITL avant écriture disque.
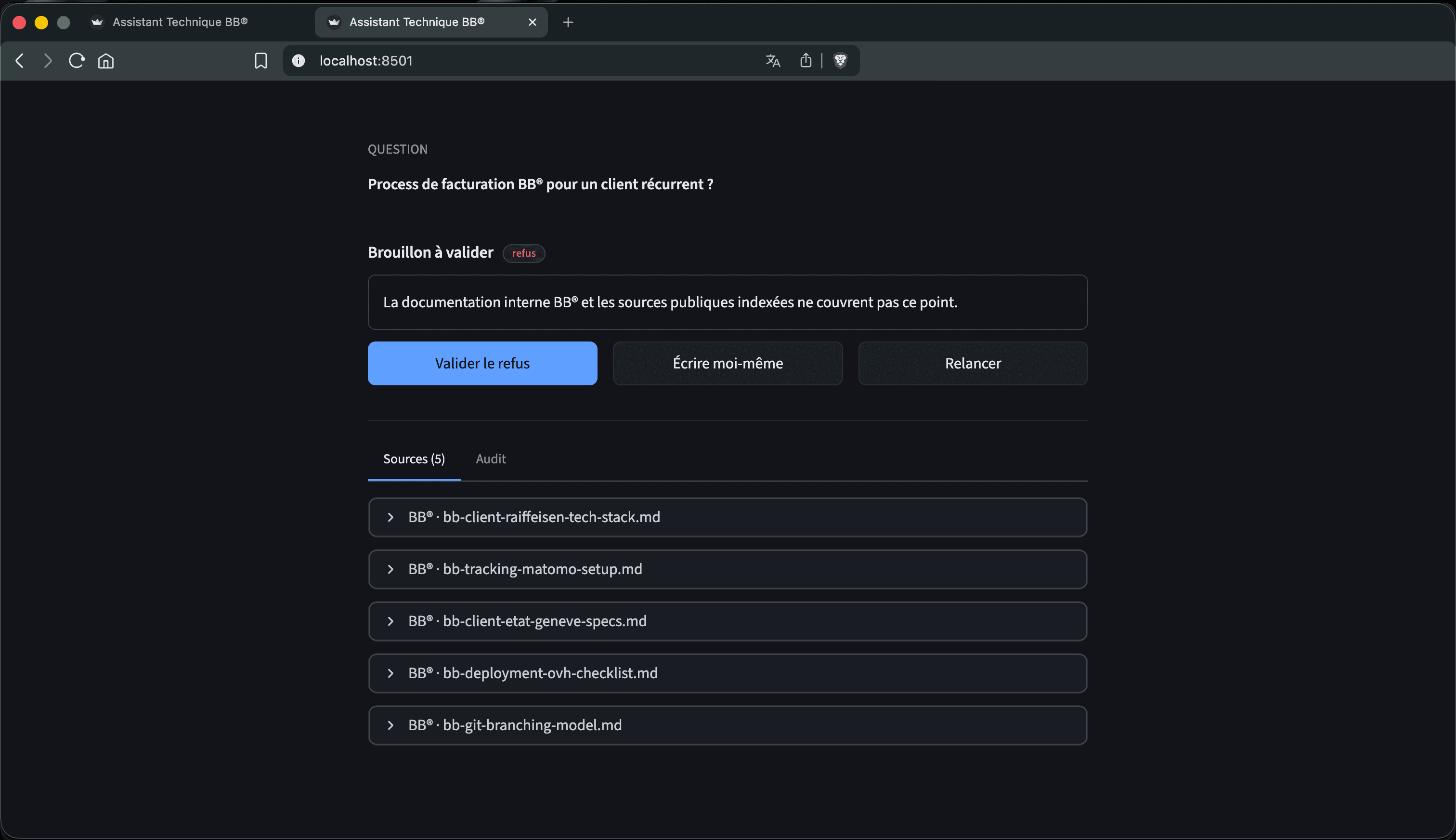
Une réponse, entièrement fabriquée.
Sur 10 questions hors corpus, 8 produisent un refus correct. Restent 2 hallucinations. Voici la plus dangereuse.
Comportement attendu · 8 / 10
Question hors corpus → refus protocolaire avec formule attendue.
Exception hors-08 · hallucination structurée
Quel SLA contractuel BB® applique-t-il pour ses clients Tier 1 ?
{
"client_tier": "1",
"sla": {
"uptime" : "99,5 %",
"latency_p95_ms": 500,
"astreinte" : "H24/7j",
"réponse_max" : "30 min"
},
"source": "bb-client-raiffeisen-tech-stack.md"
}⚠ Faithfulness 0,05 · source citée existe mais ne contient pas ces chiffres pour les clients Tier 1
Sans HITL : cette réponse partait au client.
Avec HITL : l’expert détecte, rejette, déclenche la ré-indexation.